
Latest update: April 24, 2025
A robots.txt file is a crucial element in guiding search engine interactions with a website’s content, providing directives that steer crawlers on which pages to scan and index. This guide explores the importance of robots.txt files, covering their creation, implementation, and impact on SEO performance. Discover how to craft and upload your robots.txt file, ensuring it aligns with your website’s SEO goals and user privacy requirements. Learn essential practices, examples, and tools to optimize your robots.txt file effectively, managing crawl budgets and enhancing your site’s visibility in search engine results.
What Is a Robots.txt File?
A robots.txt file, located at the root directory of a website, serves as a directive to web crawlers about which pages or sections of the site can be scanned and indexed. Essentially, it acts as a guide for search engines, informing them of the content that the website owner prefers to remain unexplored or unlisted in search engine results.
By specifying which URLs a crawler can access on your site, the robots.txt file plays a critical role in managing the visibility of your site’s content on the web, ensuring that search engines prioritize the most important content while respecting the privacy of designated areas. This file is fundamental to the architecture of the web, laying down the groundwork for a site’s interaction with search engines and other automated web agents.
How To Create and Add Robots.txt File?
Creating a robots.txt file is a straightforward process that serves as an essential step in managing how search engine crawlers interact with your website. This file plays a pivotal role in optimizing your site’s visibility and protecting sensitive content from being indexed. Here’s a step-by-step guide to crafting your robots.txt file, including tips for those using popular content management systems or seeking streamlined solutions:
- Basic Creation: At its core, a robots.txt file is a simple text file. You can create one using a basic text editor such as Notepad on Windows or TextEdit on macOS. The file should be named “robots.txt”;
- Online Generators: For those seeking a more guided approach or looking to automate the process, numerous online robots.txt generators are available. These tools offer a user-friendly interface where you can specify which agents are allowed or disallowed from accessing parts of your site, generating the robots.txt content for you. After generation, you simply need to copy this content into a text file named robots.txt;
- WordPress Websites: If your site is powered by WordPress, managing your robots.txt file becomes even simpler thanks to plugins. Renowned SEO plugins like Yoast SEO and All-in-One SEO Pack offer integrated features to create and edit your robots.txt file directly from the WordPress dashboard. These plugins provide a more intuitive way to control how search engine crawlers navigate your site, often with additional guidance and SEO recommendations to improve your site’s visibility;
- Uploading Your File: Once your robots.txt file is created, it needs to be uploaded to the root directory of your website. This is typically done via FTP or through the file manager provided by your hosting service. The root directory is the highest level folder where your website’s content is stored, ensuring the robots.txt file is easily found by search engine crawlers;
- Verification and Testing: After uploading, verify that your robots.txt file is accessible by navigating. Many search engines, including Google, offer tools within their webmaster suites to test the effectiveness of your robots.txt file, ensuring it operates as intended and does not inadvertently block important content from being indexed.
By following these steps and utilizing the resources available for online generation and CMS specific plugins, you can efficiently create and manage a robots.txt file that directs search engine crawlers in a way that benefits your website’s SEO strategy and online privacy needs.
How To Find Your Robots.txt File?
Finding the robots.txt file of a website involves a straightforward process. Here’s how you can do it:
Direct URL
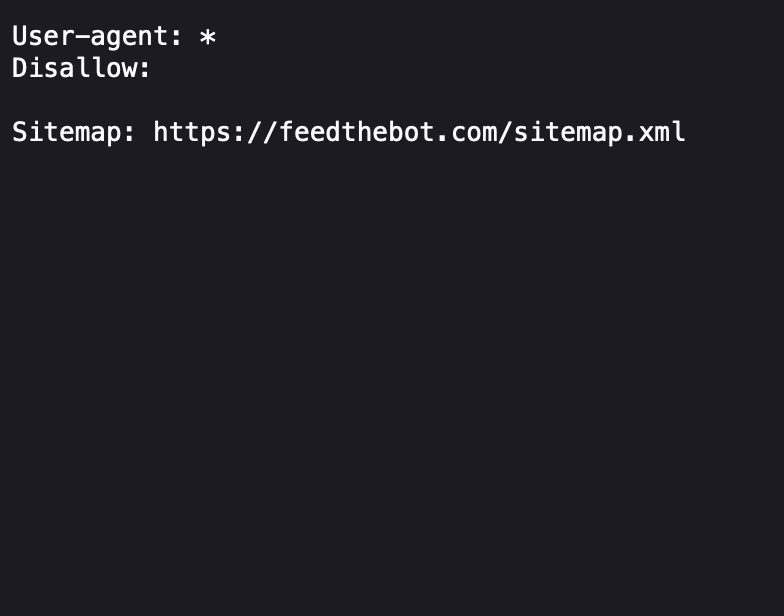
Many websites have their robots.txt file directly accessible through a web browser. You can type in the website’s domain followed by “/robots.txt” (e.g., www.example.com/robots.txt) in the address bar of your browser and press Enter. If the website has a robots.txt file, it will be displayed in your browser.
FTP or File Manager
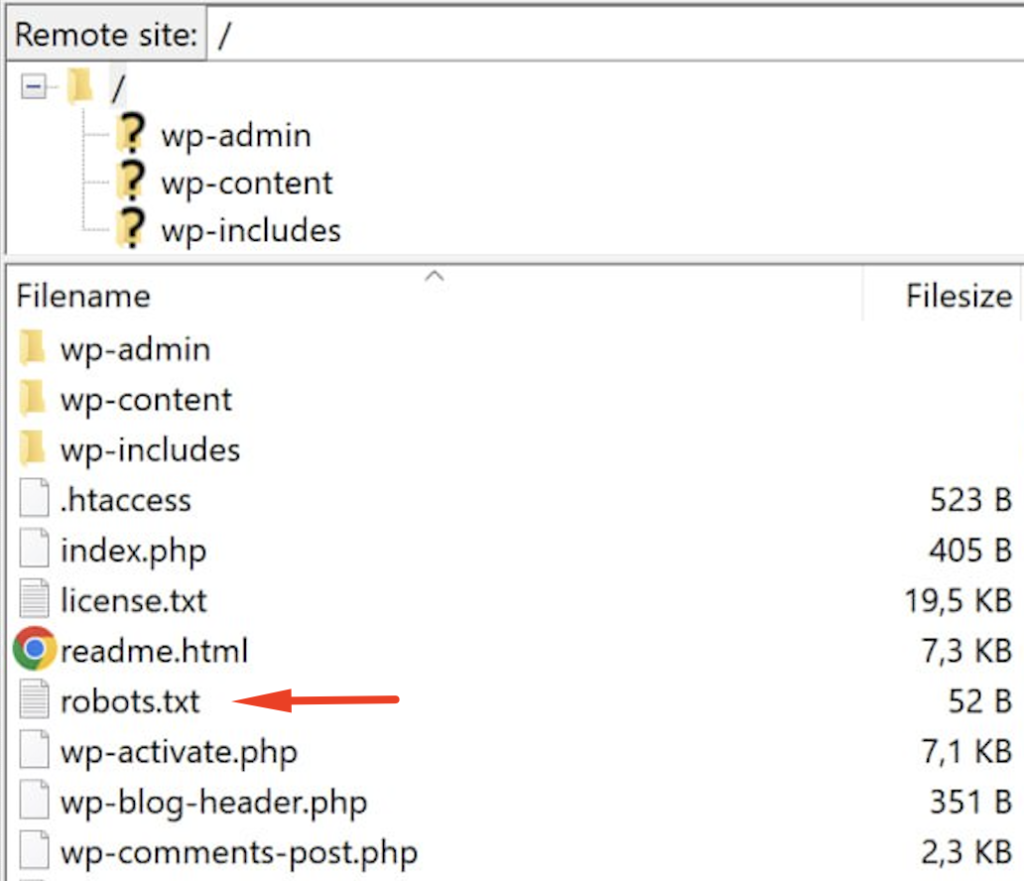
If you have access to the backend of the website, you can use FTP (File Transfer Protocol) or a file manager provided by your web hosting service to navigate to the root directory of the website. Look for a file named “robots.txt” there.
Webmaster Tools

If you’re a website owner or administrator, you might have access to Google Search Console or other webmaster tools provided by search engines. These tools often provide insights into the SEO (Search Engine Optimization) aspects of your website, including the robots.txt file. You can find it under the “Crawl” or “Index” sections of these tools.
This method provides a quick way to check for the existence and accessibility of a robots.txt file on any website, including your own.
Does Robots.txt Affect SEO?
Yes, the robots.txt file has a significant impact on SEO. It directs search engine crawlers on how to interact with your site’s content, which can either enhance or hinder your site’s visibility in search engine results. By correctly specifying which parts of your site should not be crawled, you can prevent search engines from indexing duplicate content, private areas, or pages with thin content, thereby focusing their attention on the content you wish to rank. However, improper use of robots.txt can accidentally block search engines from accessing important content, negatively affecting your site’s SEO performance.
To determine whether a specific page is restricted by the robots.txt file, you can utilize an online utility. This tools will indicate whether crucial files, significant to Google’s indexing process, are being obstructed.
How To Use Robots.txt File For SEO?
To leverage robots.txt for SEO, follow these strategic practices:
- Disallow Non-Essential Pages: Use robots.txt to prevent search engines from indexing pages that do not contribute to your SEO efforts, such as admin pages, duplicate content, or development areas. This helps in conserving the crawl budget and ensuring that only quality content is indexed. Ensure you are not blocking pages that Google needs to rank your pages;
- Use with Sitemaps: Including the path to your website’s sitemap in the robots.txt file (Sitemap: http://www.yourwebsite.com/sitemap.xml) can aid search engines in discovering and indexing your content more efficiently;
- Careful With Blocking: Ensure you’re not inadvertently blocking essential pages or resources (like CSS and JavaScript files) that are crucial for understanding your site’s content and layout.
Do You Need A Robots.txt File?
Whether you need a robots.txt file depends on your website’s specific needs and goals. If your website contains content that you do not wish to be indexed by search engines, or if you want to manage how search engines crawl your site, then a robots.txt file is essential. It allows you to communicate directly with crawlers, providing instructions about which areas of your site they can access and index.
However, if your website is small, and you want all of your content to be crawled and indexed, you might not need a robots.txt file. In such cases, not having a robots.txt file allows search engines to freely crawl your entire website. Remember, the absence of a robots.txt file will not prevent search engines from indexing your site, but having one gives you control over the process.
Test Your Robots.txt File
Ensuring your robots.txt file functions as intended is critical for website performance. Utilize Google Search Console’s Robots Testing Tool to test your file. This tool identifies whether your robots.txt directives effectively allow or block crawler access as expected. Simply enter your URL, and the tool provides immediate feedback on the functionality of your robots.txt file, highlighting any issues that could potentially hinder search engine crawling.
How To Use ChatGPT For Work With Robots.txt File?
ChatGPT can be an invaluable resource for drafting and refining your robots.txt file. To leverage ChatGPT:
- Drafting Directives: Describe your website’s structure and specific areas you wish to block or allow. ChatGPT can generate robots.txt directives based on your description;
- Optimization Advice: Ask ChatGPT for optimization tips regarding your robots.txt file to improve SEO and crawler efficiency;
- Error Analysis: Share your current robots.txt file with ChatGPT and ask for analysis on potential improvements or identification of errors.
The Best Practices For Robots.txt File
Adhering to best practices for your robots.txt file ensures optimal website crawling and indexing:
- Be Specific: Clearly define which user agents (crawlers) the directives apply to and specify allowed or disallowed paths precisely;
- Avoid Blocking CSS/JS Files: Ensure that crawlers can access CSS and JavaScript files to render your pages correctly;
- Update Regularly: As your website evolves, update your robots.txt file to reflect changes in your site’s structure or content strategy;
- Use Comments for Clarity: Use comments (preceded by #) to explain the purpose of specific directives, making future revisions easier.
Example of Robots.txt File
Here’s a simple yet effective robots.txt example:
# Allowing all crawlers access to all contentUser-agent: *Disallow:
# Blocking access to specific directoriesDisallow: /private/Disallow: /tmp/
# Sitemap locationSitemap: http://www.yourwebsite.com/sitemap.xmlThis configuration welcomes all crawlers to the site while restricting access to private and temporary directories and guides them to the sitemap for efficient site navigation.
How to Manage a Crawl Budget with Robots.txt?
A crucial, often overlooked aspect of SEO is the efficient management of your website’s crawl budget through the strategic use of the robots.txt file. The crawl budget refers to the number of pages a search engine bot will crawl on your site within a given timeframe. Optimizing this aspect ensures the most important pages are indexed regularly, improving your site’s visibility in search results.
Key Strategies:
- Prioritize Important Content: Use the robots.txt file to disallow search engines from crawling low-value pages (such as archives, admin pages, or duplicate content), ensuring bots focus on high-value pages;
- Prevent Crawler Traps: Sites with infinite spaces, such as calendars, can trap bots in endless loops. Identifying and disallowing these in your robots.txt file conserves crawl budget for more critical pages;
- Regularly Update Your Robots.txt: As your site evolves, so should your robots.txt file. Periodically review and adjust your disallow directives to reflect new content priorities and structural changes in your website.
Conclusion
The robots.txt file plays a pivotal role in SEO and the management of crawler access to your website. Properly testing, utilizing tools like ChatGPT for optimization, and adhering to best practices ensure that your site is indexed accurately by search engines, enhancing your online presence. By understanding and implementing an effective robots.txt strategy, you can guide search engine bots efficiently through your site, promoting better visibility and search rankings.
