
Latest update: April 16, 2025
Getting Google to crawl and index the pages should be a priority for any website owner. Even when you do everything right with the optimization and follow all the rules, you still might experience some problems. The “Blocked by robots.txt” error in Google Search Console is one of them.
We want to help you understand what this error means and how you can handle it. Otherwise, your site will be practically invisible to potential visitors.
So, keep reading!
What Does “Blocked by robots.txt” Error Mean in GSC
The “Blocked by robots.txt” error means that Googlebot can’t crawl certain pages on your website. This happens when restrictions in your robots.txt file prevent Google from crawling certain pages.
Google won’t index content that it cannot access. This can significantly affect your site’s visibility in search results.
What is This File Exactly?
Robots.txt is a simple text file in your site’s root directory. It provides directives to the crawlers. Basically, it instructs them on which pages or sections they are allowed or disallowed from crawling.
Main Reasons of “Blocked by robots.txt” Errors
There are many reasons why this error might appear in Google Search Console. We gathered the main ones below.
Accidental Disallow Rules
Sometimes you might mistakenly block important pages when configuring the robots.txt file. This usually happens because of:
- Human error;
- Misinterpretation of directives;
- Copying over incorrect rules from another site.
Blockage of critical landing pages or product pages might seriously impact your rankings and organic traffic.
Intentional Blocking

Certain areas of your site should not be indexed. It includes:
- Login pages;
- Internal search results;
- Private user data, etc.
You should block unuseful pages in robots.txt to keep them hidden from search engines.
However, you might have some visibility issues when you unintentionally add key public-facing pages to the disallow list.
Changes in Website Structure
The robots.txt file might be changed to restrict access temporarily when your website undergoes:
- Redesigns;
- Migrations;
- Core website updates.
Sometimes, developers may block entire sections of the site and forget to remove those restrictions after launch. As a result, browsers can’t discover new or updated content. It delays indexing and ranking improvements.
Misconfigured CMS Settings
Many CMS solutions have built-in settings that automatically generate a robots.txt file. They can restrict Googlebot from crawling pages without proper configuration.

For example, WordPress has an option to “Discourage search engines from indexing this site.” It can inadvertently block all pages if you enable it by mistake.
Step-by-Step Guide to Fix “Blocked by robots.txt” Error
You already know which effects the “Blocked by robots.txt” error can cause. It is really harmful from the SEO perspective.
Now, you probably want to know how to resolve it. So, here are the steps you have to follow.
Step 1: Find the “Blocked by robots.txt” Error using GSC
The first thing you have to do to fix this problem is identify which pages are being blocked by the robots.txt file.
First, log in to Google Search Console and access your account. Select the site where you’re experiencing the issue.
Then, go to the “Pages” section. It will give you an overview of indexed and non-indexed pages.
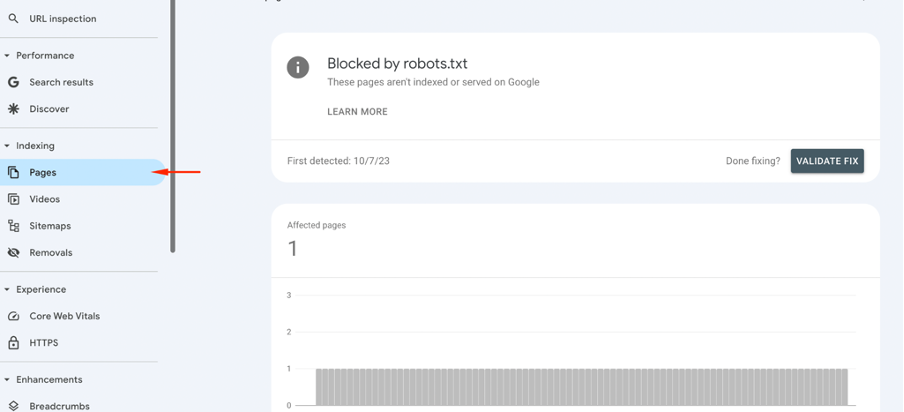
You’ll see the Why pages aren’t indexed. Here, Google lists pages that were prevented from crawling. Click on the affected URLs to find which pages have problems.
You can identify if these URLs should remain blocked or need adjustments in the robots.txt file here.
Step 2: Review Your robots.txt File
Next, you need to check your robots.txt file. It will help you find the directives that stop Google from accessing your pages.
Start by opening a web browser and entering your domain followed by /robots.txt.

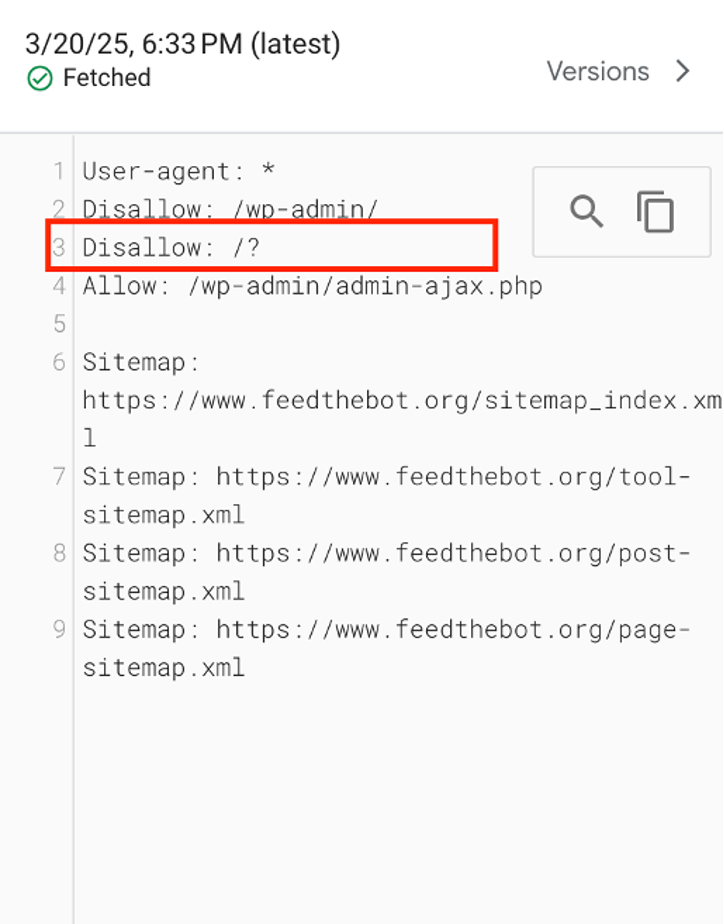
This file has rules that specify which parts of your site should or shouldn’t be crawled. Look for entries that include Disallow: followed by a URL path.
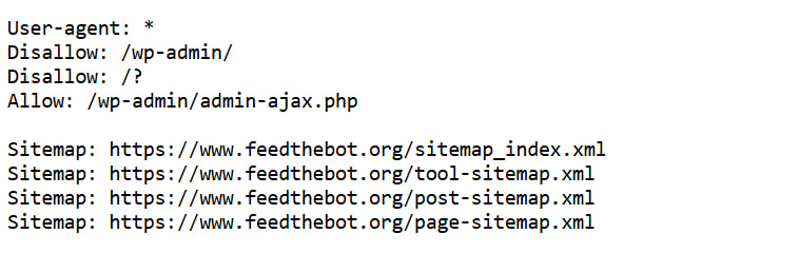
This rule doesn’t let the search engines crawl /important-page/.
So, determine if the block is necessary. For example, admin pages or login pages should remain blocked for security reasons. Important blog posts or product pages should be accessible.
Step 3: Edit the Robots.txt File
You need to update the robots.txt file after you determine the pages that can’t be blocked.
You can edit it through the file manager or an SEO plugin if your site runs on a CMS. For other websites, we recommend using an FTP client or a text editor to modify the file.
You have to remove or adjust the blocking rule. Find the Disallow: statement we mentioned above that blocks any important pages and change it to Allow:.
If you only want to allow Googlebot, you can specify it.
Finally, upload the updated robots.txt file to the root directory of your site after making all the modifications.
Step 4: Use a Robots.txt Tester
Your next step is to confirm whether all the changes are correct. Google Search Console provides a tool to verify your robots.txt file. You can test if Google can access specific URLs.
This instrument allows you to check the correct configuration of the rules.
You just have to paste the URL of the blocked page into the tester. Then, click on “Test”. It will show you if the page is accessible or still blocked.
If you still see the “Blocked by robots.txt” error, go back to your file. Make sure there are no conflicting rules.
Step 5: Reindexing using URL Inspection
Next, you should request Google to recrawl all the updated pages.
Go to your Google Search Console and open the URL Inspection tool. It will help you verify the current status of the page.
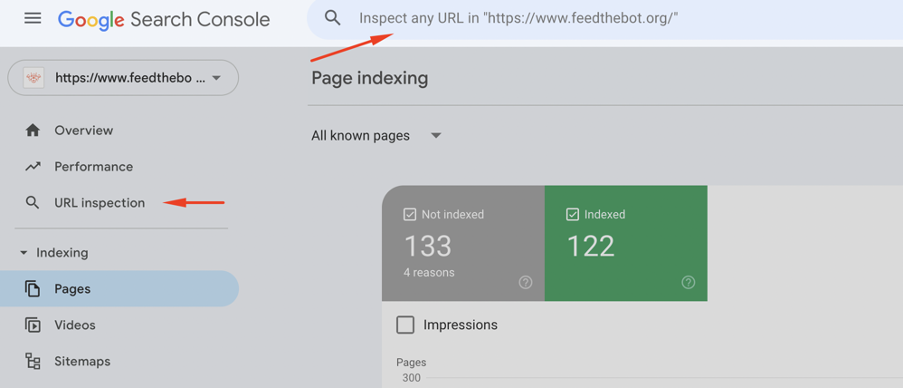
Make sure to check the “Page Indexing” details.
Next, you should click on the “Request indexing” button. It tells Google to re-crawl and index the page as soon as possible.
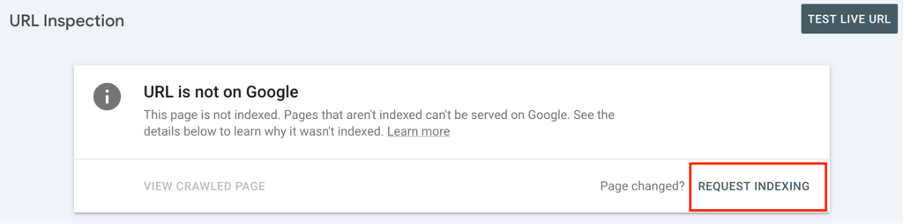
Remember, that it might take some time to process the request. So, check back after a few days.
Step 6: Monitor and Verify
You need to regularly monitor your pages even after fixing the problem. It is essential to ensure that similar situations don’t appear in the future.
After a few days, check Google Search Console again. Look under “Indexing” to see if the error no longer exists.

Also, you might use the site: search operator in Google to check if the page appears in results.
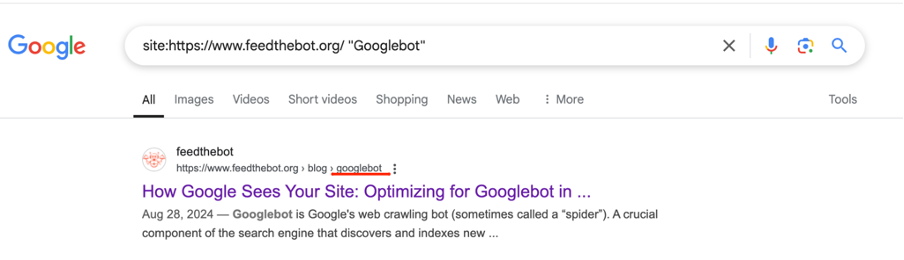
Review and update your robots.txt file from time to time. It will help you prevent accidental blocking of important content. Plus, I recommend you periodically use the URL Inspection we mentioned before.
Key Takeaways on Fixing “Blocked by robots.txt”
- The “Blocked by robots.txt” error in Google Search Console means Googlebot is prevented from crawling certain pages due to restrictions in the robots.txt file;
- Common causes include accidental disallow rules, intentional blocking of private sections, website structure changes, and misconfigured CMS settings;
- This error can harm SEO by preventing indexing, reducing site visibility, breaking internal links, and negatively affecting user experience;
- To fix the issue:
- Identify blocked pages in Google Search Console.
- Review and update the robots.txt file to remove unnecessary restrictions.
- Use the robots.txt Tester tool to validate changes.
- Request reindexing in Google Search Console.
- Monitor and regularly check for issues to prevent future errors.
- Proactively managing robots.txt helps maintain proper indexing, SEO rankings, and user experience.
If you encounter other errors, refer to our Google Search Console guidelines to resolve them.
